I guessed that it would have made more sense to attack in complete darkness towards mid-march, but it appears that the US and Israel aren’t worried about Iran’s anti-air capabilities. The ten days turned out to be bullshit and Trump couldn’t wait any longer. Everything he claimed Obama would do about attacking Iran has turned into a confession. Apparently the discussion of Trump having committed sexual assault against a minor was getting too hot.
While it appears the US and Israel have free reign in the Iranian sky, they are not going to land troops. I’m not even certain they really think there will be any kind of popular uprising. If the IRGC is hit, that will hamper their ability to respond to revolts, but it will not stop it. They will likely already have dispersed, making it harder to score decisive hits on their leadership, infrastructure, or personnel. They will continue to attack external targets where they can. The guards will drop anyone they think is an agitator, with an “I don’t have time for this bullshit” attitude.
And we’ve seen where Trump went into Venezuela for regime change but left the regime in-tact. Ultimately, as we discovered in Iraq and Afghanistan, you can’t keep a government in power or eject a government with just air strikes. And if the people don’t want the government, no matter how good, it will not succeed. There will likely be no regime change. There will just be a number of dead Iranians. Maybe some destroyed materiel, but we’ve seen they can reconstitute it fairly quickly.
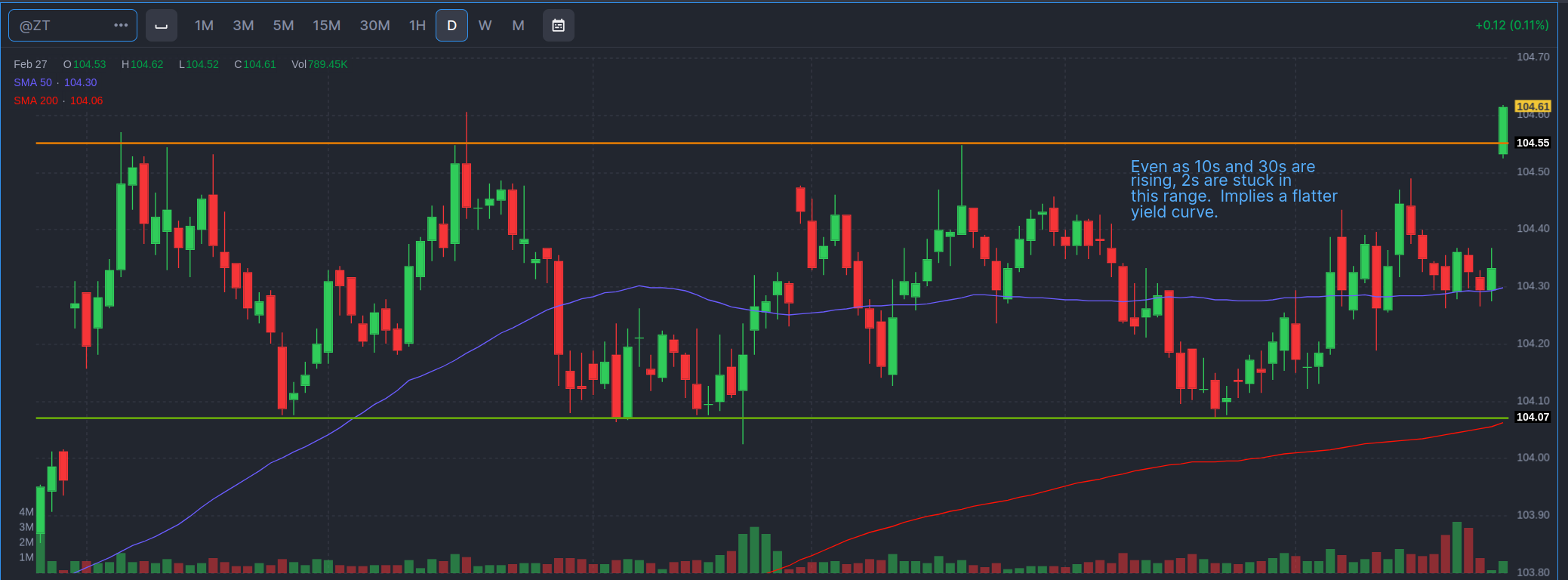
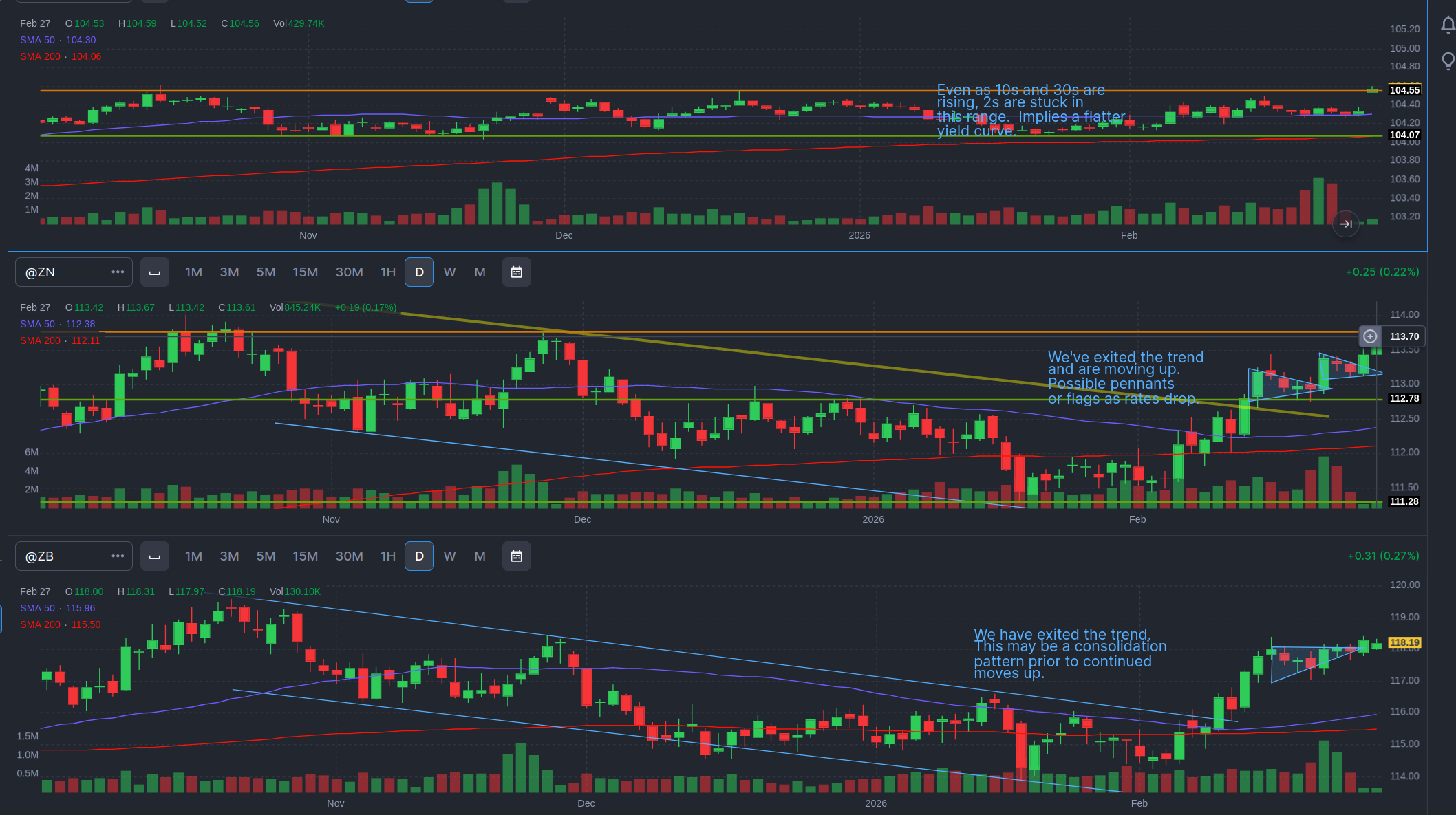
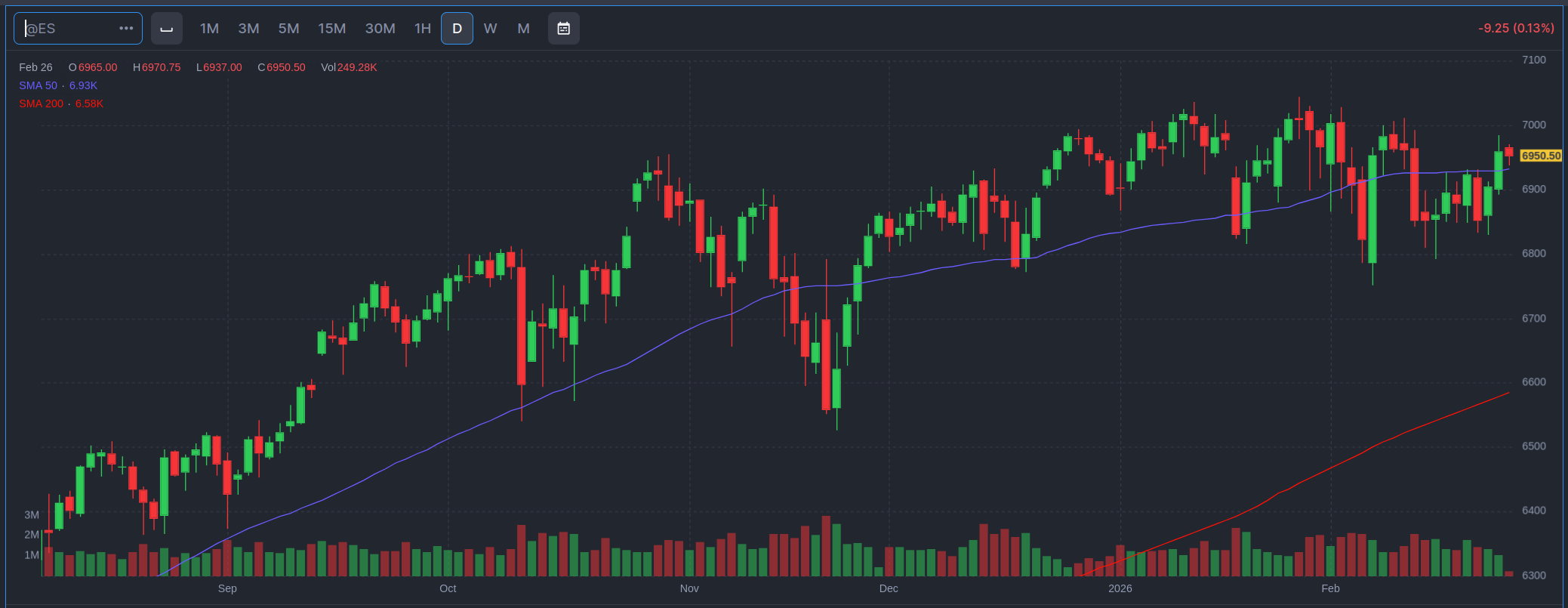
Just in time for me to point out the 2 year was stuck and that meant curves are likely flattening, it breaks out above its range. There is a big caveat to this. Just because it breaks out, does not mean a true break out. It’s going to need to close above the range and have at least one complete body outside the range before I’ll start to believe it’s a true breakout. It could just retreat today, leaving the wick, and maybe not be a breakout. Also, ranges should be thought of as regions. Just because I drew a line 1 pixel wide, does not mean it’s tick wide. It should be thought of as “around this area, sellers tend to show up.” If it exits the range, it means the sellers are not showing up and there is net buying.
Looks like the two-year finally broke out of its range. At the same time the 10 year is popping. That keeps the yield curve in contago. Setting aside the gap up (which is kind of violent for the 2 year bond future). Maybe we expect the Fed to really inject more liquidity as the cockroaches come out? Dunno. The Fed has been active in the Repo markets, which usually means they’re adding liquidity.
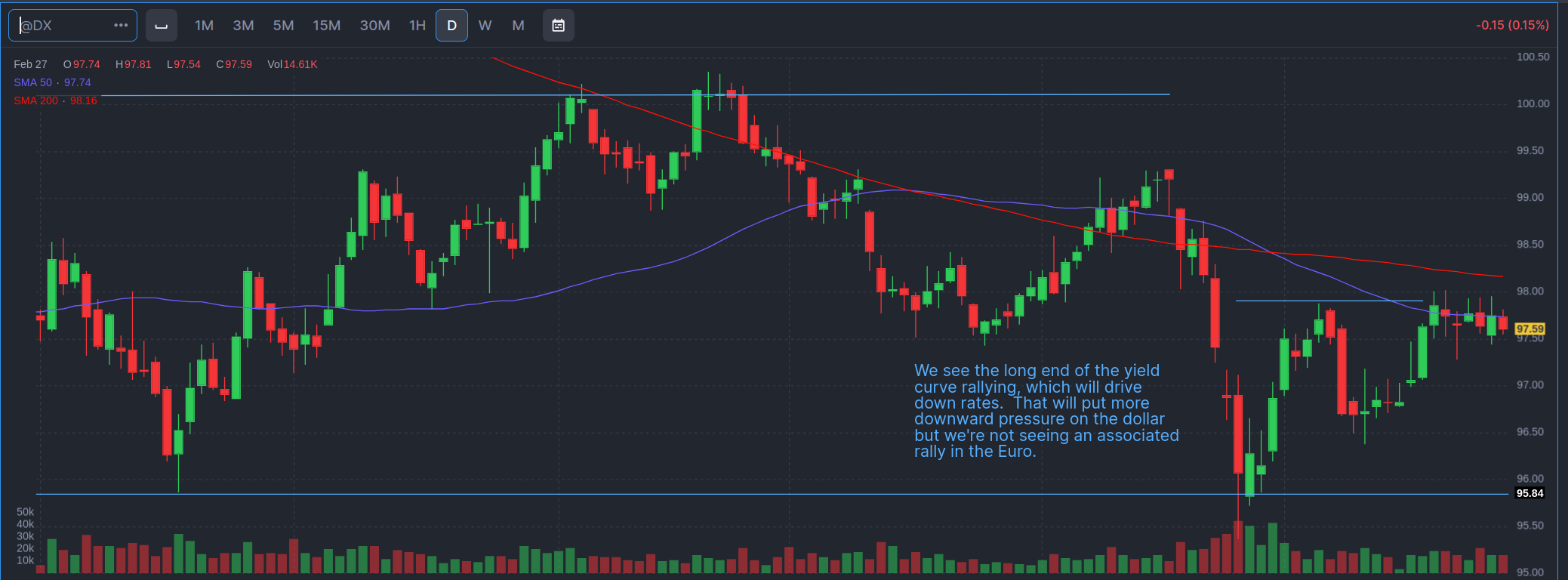
That keeps downward pressure on the dollar. That suggests the dollar will continue to erode. As the interest rates drop, it makes other bonds or investments, or just holding cash, more attractive. That reduces the demand for dollars, and therefore the dollar will fall against other currencies. The weird little resistance area was originally just a marker looking for a higher high, if the dollar is pulling up, because we got a higher low. However, this might be forming a wedge.
Which will continue to push up commodity prices, like oil, which will fuel inflation. Which will limit the Fed’s ability to bring down the Federal Funds rate. But it will impact peoples’ sense of affordability. It’s why you could go into recession, the dollar tanks, but commodities (like food and energy) get more expensive. Core inflation (those sneaky little devils always exclude food and energy), may drop, but what a consumer feels may not improve all that much.
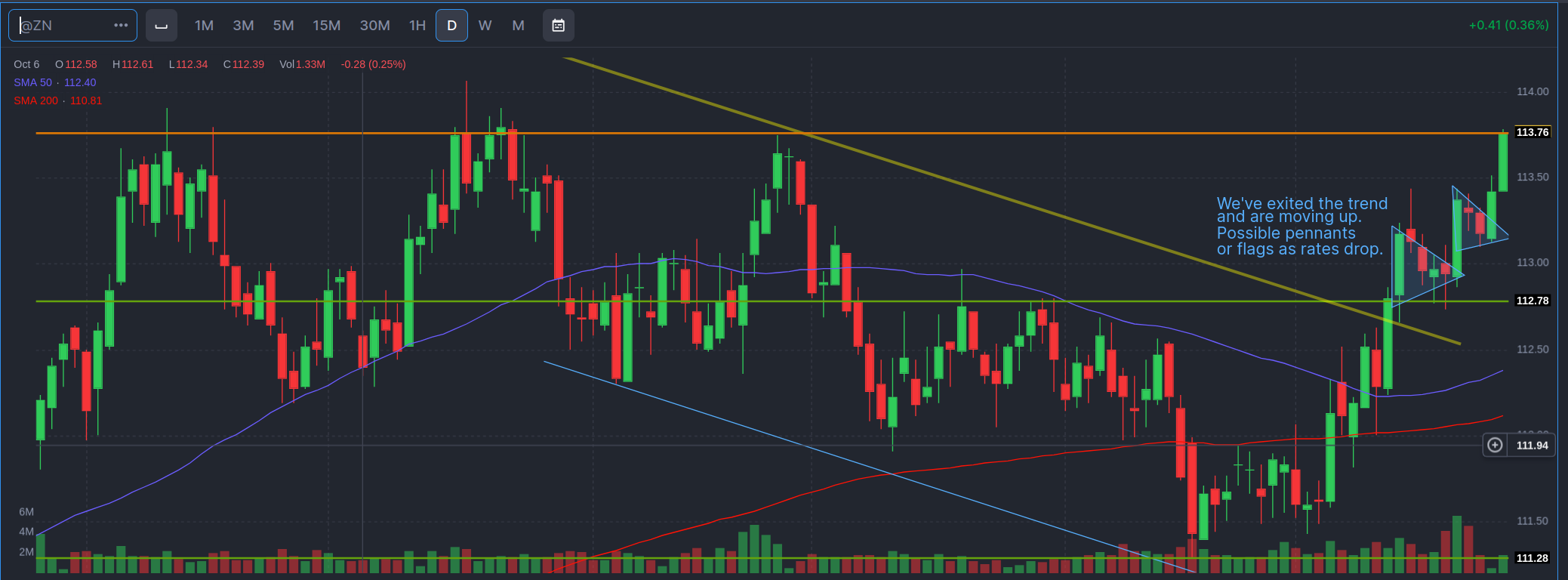
On the 10 year I identified two possible pennants. What do they mean? Does it mean the price will always go up because the pennant exists? No. The pennant is just a price pattern that tells me when sellers showed up to take profit, the buyers didn’t cave. They stepped in. That’s all. It tells me there’s buying energy there for the 10 year bond. And if I were to bet on a direction, it would be toward higher prices. But I don’t bet on it, because chart patterns are not a guarantee of future performance. They are also a Roschach test and subject to interpretation. You might only see the pennants because I pointed them out, not because you would have seen them. And I might be wrong. I might be misreading the price action. So I would never buy or sell based on a chart pattern.
This is not investing or investment advice to you, or anyone. It’s is provided for your entertainment purposes only. And if you are investing, contact a professional before making any decisions. Buying and selling stocks, futures, or any investment is a risky activity and can cause you to lose money, including the principal which you invest.
Taken about 8:45 AM EST in the pre-market. In short, this is the PPI coming out hot. 2.9% annual inflation versus and expected 2.6%. For the market this is as bad as, if not worse than, the CPI coming in hot. If the CPI comes in above estimates, that just means rates might rise. But if the PPI comes in hot, and the CPI doesn’t, it means margins get squeezed. It means that for a $100 of revenue, it means less profit. If both CPI and PPI were going up, that’s not good, but businesses are able to hold their margins. As happened earlier in the inflation burst, CPI went up faster than PPI in some cases, and margins expanded.
That explains some of the impact. The other part of it is the idea that AI isn’t playing out the way people hoped it would. We are seeing a concerted push by companies to adopt AI and (despite the protestations of $XYZ – Block), we have yet to see significant changes in productivity. There may be reasons for this that have nothing to do with AI. First and foremost, it’s a new technology. The “recipe” for mixing it into an organization to boost productivity and reduce costs may need to evolve. With a lot of churn, it’s hard to know if chat bots, RAG (retrieval assisted generation), or some yet undiscovered pattern will produce the best outcome. One that doesn’t give away free stuff from vending machines or cite non-existent cases in court filings. (So, how much do you want to trust an LLM to correctly categorize a major business expense that could cost you in interest an penalties?) But until we do it looks like NVidia may be the only winner as they sell more GPUs to companies that may not have the electrical grid power to turn them on?
But let’s get back to macro. Long rates are dropping, but the 2-year is kind of holding in a range. These are bond price futures, meaning when they go down, interest rates go up. (The price of a bond is the inverse of the rate). The bottom two are 10 and 30 year bonds, respectively. Businesses are generally sensitive to the 10 year rate. Prices were falling on the 10 and 30 up to February, ,while the 2 year stayed in its trading range. (I kind of compressed the 2 year graph to give a better sense of how little movement there was in the 2-year, given a similar $3 range in the 10 year). The fact that long bond prices were going down, while shorter term maturities were stuck, meant that long rates were coming down while short rates were holding. (The shorter you go the closer you track the Fed Funds rate).
A normal yield curve has the lowest rates for the shortest maturity debt. Everything beyond that carries more risk. These risks may be interest rate risks (the interest rate falls and so the price of your bond falls), or re-investment risk (the rates go down and you can’t re-invest at the same rate). There’s almost no risk at 30 days to 90 days. At thirty years, there’s almost a certainty things will be different and you might be underwater in your bonds or unable to secure a similar rate when the principal redeemed. The price of the bond is a negotiation between buyers and sellers about future interest rate risks.
When the price of long bonds start going up, it means that people are betting future rates are going to be lower. This is because they expect lower demand for capital in the future – likely because the economy is slowing. A rate inversion, when the rate on the long bond falls below the short rates, is a sign investors expect the economy to be in recession so rates will be reduced to stimulate the economy. That’s why we get yield inversions, and why they tend to be at the start of, or just in front of a recession. Also, in most cases, the short term rates go up because the Fed has been slowing the economy. This last inversion period was both large in scope and did not result in a recession, so far1. (And there won’t be as much borrowing to invest in new businesses). What you want to see is the entire yield curve (the interest rates at various maturities) move down together. Lower rates plus strong future expectations.
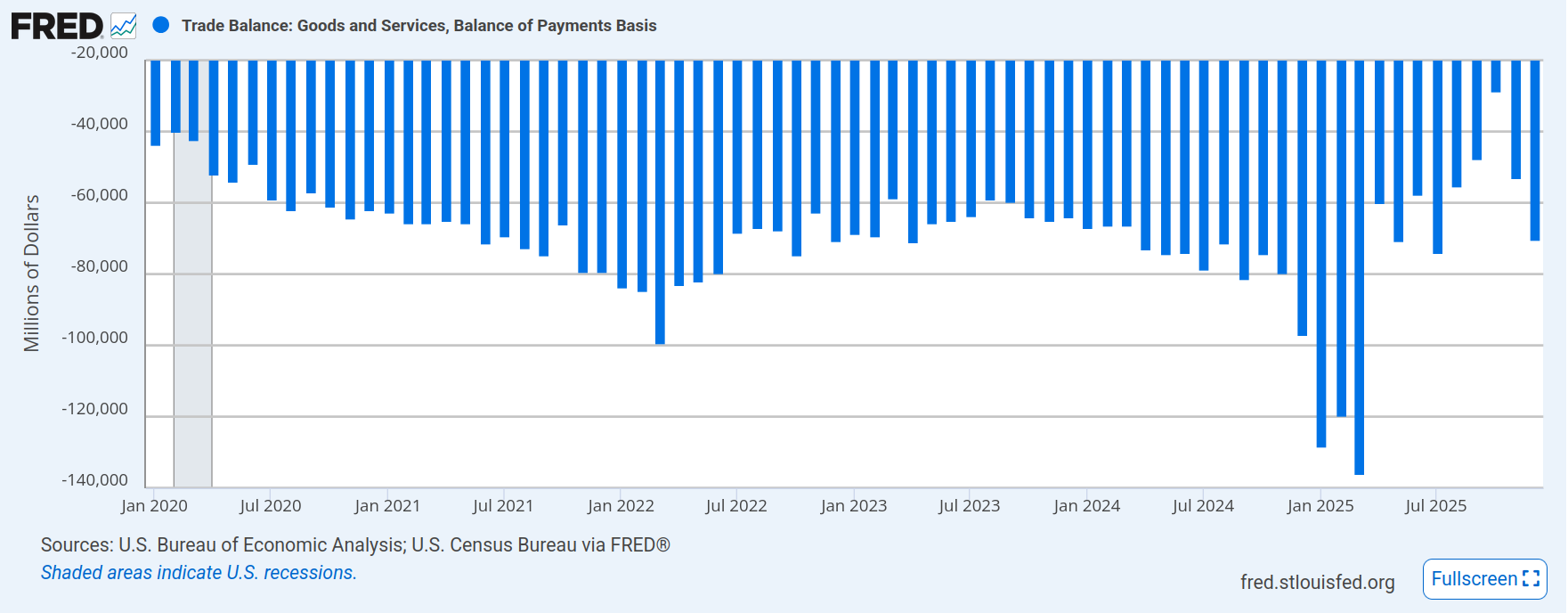
Which brings me to this graph, the balance of payments (trade deficit). If you eye-ball a line across the graph, between -60,000 and -80,000, you probably have close to the average trade deficit. Then you have “Liberation Day” in April and a huge spike. What’s that about? Those are businesses bringing in inventory prior to the tariffs taking effect. That inventory was spent down in the next few months, as businesses imported less because their inputs were sitting in warehouses. At some point they are going to have to bring in more product, and that’s why I think we’ll be back to roughly the same (maybe a hair smaller) trade deficit. We’ll have to see how it plays out, but the last reading was in line with the historical average.
That suggests that businesses are continuing to import final goods and inputs for their manufacturing at nearly the same rate as before the tariffs. Some businesses elected to eat the tariffs (note it is businesses that pay tariffs, not governments) rather than pass those costs onto consumers. They were assuming the tariffs would get rolled back and it’s better not to piss off your customers. They might even get refunds. But given the number of businesses that sold the refund rights to Lutnick’s kids at 20 cents on the dollar (yes the same one working for the president as the secretary of commerce), I don’t think they held out high hopes. We’ll have the lovely spectacle of the commerce secretary’s kids suing the federal government for refunds of illegal tariffs imposed by the administration, which they scooped up at bargain basement prices. Ain’t corruption grand?
If businesses are importing as much, and they are paying higher prices, and they have spent down their inventory, we might FINALLY start seeing the consumer level inflation impacts of tariffs. But we’ll first see it at the business level. Businesses have eaten the tariffs, for now, but will either suffer lower margin or start passing on those costs. That means businesses will start cutting costs to deal with tariffs and the easiest way to cut costs is to reduce head-count. When people no-work they no-spend. Block’s hope is the reduction in headcount (maybe over-hiring a few years ago), will result in better margins as costs fall, even if revenue falls. But, like I said earlier, there is no clear indication we’ve figured out how to incorporate AI into businesses or operate an AI provider profitably. It’s all subsidized by giant pools of investor money.
If you expect a softer economy (not radically expecting recession tomorrow), you want to hedge your risk (equity) exposure by buying bonds. Foreign companies have become a lot more wary of buying bonds, except there is no other currency with the depth of the dollar. And therefore US debt is still attractive. (TINA – there is no alternative right now). If short rates hold up because inflation actually starts making its way into the consumer market (not in one quick burst but trickling in as business after business has to raise prices), and the Federal Reserve can’t cut without resuming inflation, you should expect the economy to slow. By how much? I don’t know, but I would not expect long rates to stay where they are. I expect them to come down, or there is an increase that the Federal Reserve would need to step in by shoving liquidity into the system.
The two year has been betting the interest rates will stay about the same. Until February, the long rates were making similar bets (or maybe a little AI optimistic combined with nervousness about the Fed forced to cut rates combined with dollar de-risking). They were holding or going up slightly. Now they’re falling, compressing the yield curve. At the same time business costs may be going up. With a Fed that can’t immediately inject liquidity until the economy gets a lot worse. What a lovely little shit-show we’ve built.
This is not investing or investment advice to you, or anyone. It’s is provided for your entertainment purposes only. And if you are investing, contact a professional before making any decisions. Buying and selling stocks, futures, or any investment is a risky activity and can cause you to lose money, including the principal which you invest.
It may be the ONE TIME that the Fed slowed the economy but didn’t throw it into recession. The so-called soft-landing. Something I did not think could be done and therefore missed out on some returns (albeit at a higher risk). ↩︎
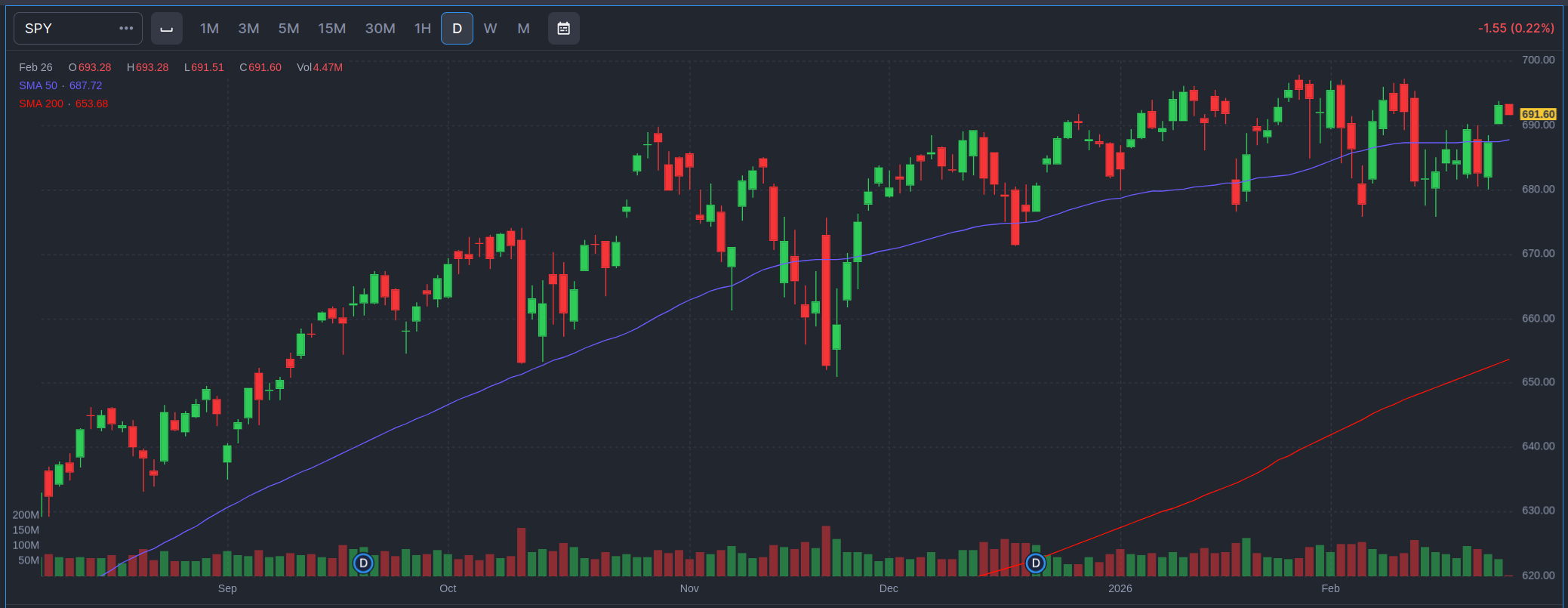
This is the “cash” index ($SPY) for the S&P 500. That’s different from the index that most people look at, which is actually the price of a futures contract on the S&P 500. The price action is a little different, but not radically different. But the S&P 500 that everyone talks about in the news is actually an expectation of the S&P 500 price in the very near future, traded almost continuously. So there are fewer gaps in the price action. The cash index primarily trades during normal trading hours in the US. The chart below is the futures contract and is smoother, with fewer gaps, but it’s basically the same movement.
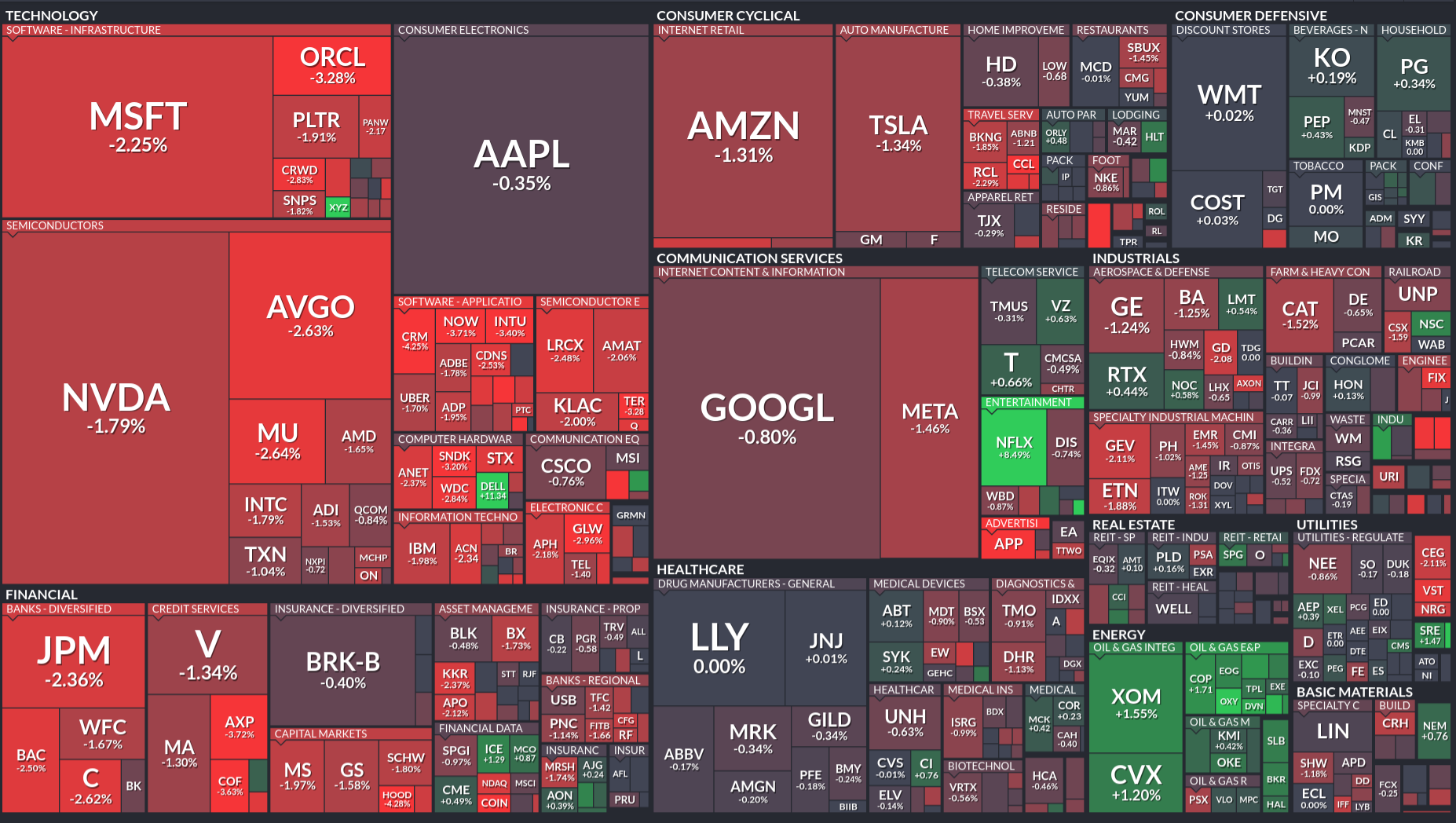
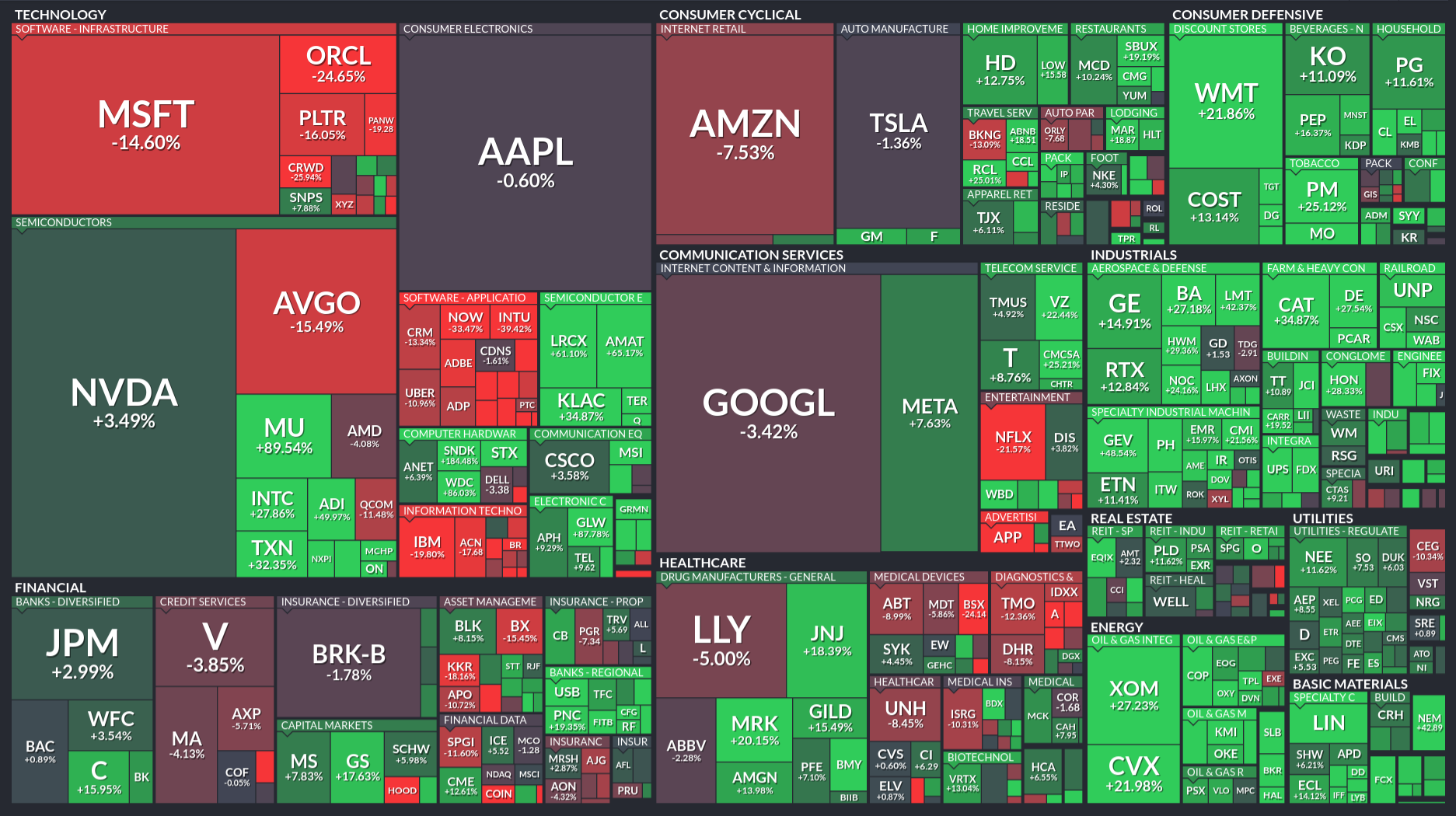
But what is it really? It’s the behavior of the 500 companies included in the index. The 500 best companies? The 500 most representative companies? The 500 largest companies? Yes and no to all of those questions. These companies fall into sectors: technology, consumer cyclical, consumer defensive, financial, communication services, healthcare, industrials, real estate, utilities, energy and basic materials. From the heat map below you can get a sense of their relative size and how they’ve performed over the last three months. Sorry, if you’re red-green color blind, but for squares that are large enough, you get the percentage change.
We have different stories about the expected behavior of the sectors under different economic conditions. For example, during a recession, when people are losing their jobs, we expect consumer defensive stocks to hold their value while consumer cyclical stocks to fall. And if we look at the 3 month performance, we can see that defensive stocks have out-performed the aggregate cyclical stocks. These stories aren’t perfect, like maybe TJ Max (TJX) is doing okay because people are bargain hunting more, and maybe McDonald’s (MCD) is doing better because people can’t afford nicer restaurants.
We’ve had a set of contradictory stories. Financials have hit hard, and consumer cyclical and communication services and technology have been meandering to falling. That suggests a slowdown. But material providers, energy, and industrial stocks are rallying. That suggests the early part of a recovery after a recession, when output is picking up. And consumer defensive and utilities are doing great, which is a sign of a slowdown.
What might be going on? I suspect there are two sets of behaviors. Part of the behavior can be ascribed to macro-economic movements and part can be ascribed to idiosyncratic movements. Idiosyncratic is really a short-hand way to say the fish is swimming upstream for a different reason than the current is moving the rest of the fish down stream. I think, in part because the yield curve may be flattening, that the market is anticipating an economic pullback.
That explains the behavior that utilities, financials, consumer cyclicals, consumer defensives, technology, and communication services are exhibiting. I think any strength in technology is coming from the AI bubble. The AI bubble is powering some of the industrials, along with a re-arming of Europe and a possible expansion of the defense spending. The policy chaos and dollar de-risking explain energy prices and basic materials. If the dollar de-values, then the price of commodities and energy will increase for American consumers. If the dollar falls, without doing anything, Exxon Mobile (XOM), Chevron (CVX), etc. will make a lot of money. As will miners.
So here’s the score card. The long term bet being made by most investors appears to be for a weaker economy. That’s not certain. They can be wrong. But that’s what most of the sectors are telling me. (And therefore I could be wrong). My confirmation is that maybe the yield curve is flattening. (But I could be wrong). The dollar is expected to weaken (as per official US policy), and falling interest rates will further weaken the dollar beyond the chaos that is driving countries away from the dollar. That means energy and basic materials have a tail wind. Until such time as we demand less energy because economic activity slows down, and even then we could see prices increasing on net.
Anyway, that’s how I square the circle.
And this is not investing or investment advice to you, or anyone. It’s is provided for your entertainment purposes only. And if you are investing, contact a professional before making any decisions. Buying and selling stocks, futures, or any investment is a risky activity and can cause you to lose money, including the principal which you invest.
We have no visibility, or little visibility, into the fraction of the GOP that feels comfortable with right wing social policy, but is there for economic reasons. Or pseudo-economic reasons. I once had a discussions with someone who felt it was worse to go from a top marginal rate of 33% to 40% on his federal income tax, even if his income doubled. The funny part is he cited the state and local taxes he used to pay, as a New Yorker, but no longer had to pay since moving out. The hilarious part, given his job, is I doubted he was very far in the 28% bracket. Or people with almost no active trading screaming about equal treatment of capital gains and regular income, even if their house (by far their biggest capital gain) were exempted.
Sometimes peoples’ views on taxation have less to do with reality than with their status as temporarily embarrassed billionaires. Or vague notions that the “job creators” would leave the country if we taxed them (like they’re moving to Florida and Texas from New York… sort of). I’m not sure where they would go. Maybe they would try to move their business to low tax jurisdictions, like Europe, or where they might have a less heavy government hand, like China. Or that they would decide the next marginal dollar just wasn’t worth it. And would “slack off,” as if they did everything at the family offices or companies they helm. These are people who’d gladly trade your grandmother for a nickle.
These idiots may code socially liberal, like their favorite niece or nephew is “trans” and they are careful about pronouns and dead-naming. Or they might be gay. But have no problem backing bigots. Or enjoy recreational drugs, especially of the mind-expanding variety. Although I sometimes wonder if they’re using them correctly. They know it’s not a suppository, right? Abortion is okay. Although they don’t get too bent out of shape over taking rights from women. They love crypto currency because of some strange notion about a broken fiat-currency system. Some are staunchly independent, except almost always vote Republican because they think government is out of control, or would like to see a balanced budget. (Something no Republican has done since maybe Eisenhower,). But they would rather talk about sports, crypto-currencies, or video games.
Because they code two ways, I suspect they throw off our sentiment about the country. They might answer a survey saying they are unhappy with the way that Trump is running the country. They may express ire at rounding up immigrants, although they will also talk about “doing it the right way.” They might have liberal girlfriends or wives, or conservative girlfriends or wives, and write “that stuff” off as their partner’s thing. They’re independent. But they will vote Republican at the national level. They’re not Republican, they’re independents, and will point to (for example) supporting someone like Spanberger in Virginia. You know, a “normal” Democrat. But when push comes to shove, at the national level, they have pulled the lever for Trump, more than once, if not all three times.
I suspect status and other grievances in their psyche may play a bigger role in how they vote. Even though they code liberal they like to think they’re a man’s man. (And if you haven’t figured it out – I’m talking about men in particular). Some of them are well educated, even if they haven’t opened a book for pleasure since college. They are not having the career or age of adult manhood they anticipated. Something I suspect they covet, as they prefer super-hero movies, John Wick, or the “pre-woke” Lord of the Rings. They tend to listen to man-o-sphere podcasts. I think there’s definitely an aspect of anxiety about their position and their power. (A lot of them are technically adept but feel they lack power or feel they are bossed around).
This mass of mostly men (almost exclusively men) are part of the reason the mid-terms will be so hard to predict. The expectation, which if the vote were held today I think would be certain, is a wave of anger pushes even safe Republicans out of power. We wind up with a flipped House and Senate. But I’m already seeing more right-wing content show up in my social media feed, so we have to deal with that bleeding off the weak over the next 8 months.
If they view the election as a chance to reign in, or course correct, the president, they may vote for Democrats. Especially since they know the president makes all the decisions, but “congress has a role.” Voting for a Democrats might tell the Republicans to back it off a little. Or, if they are well managed and well messaged by the stupid amount of money that will be coming from the Ellisons, Musk, or any one of a number of injured billionaires, they may ride or die with the Republican party. Woke democrats will be out of control. And when they pull that lever, they think they are doing so as Frodo, not some anonymous orc in Sauron’s armies. After all, they are independent voters.
“The Looming Taiwan Chip Disaster” asks a question many are wondering. If China blockades and invades Taiwan, what is Apple going to do? It gets many of its chips from Taiwan and TSMC manufactures its very custom CPU. A blockade or invasion would cut Apple off from TSMC. That would be the end of Apple products, right? So why haven’t Apple and other Silicon Valley companies diversified out of Taiwan to at least have capacity in the United States. Let me tell ya… business idiots are beyond your tiny brain. They understand a broader, global picture that they have to carefully consider. They had a great press event in the oval office to announce a lot of stuff about sexy advanced chips. They even gave Trump a gold thingy for his desk. They’re saying things and doing things you can’t understand. So let me help break it down for your tiny (non business idiot) minds.
First, let’s start with a larger problem, that you can’t just fabricate (fab) a CPU and you’re done. This is part one of that problem, and it’s packaging. Once the silicon is etched and cut into separate chips, it needs to be packaged. This is not just slapping a bunch of plastic or ceramics around the chip. A poorly packaged chip will show problems that prevent it from operating correctly. And modern packaging is a far cry from the 1970s DIP modules, pictured below. A DIP packaged chip might have 40 or so connections. A modern chip can have hundreds of connections. And it may be housed in the same package with other chips, either support chips, or because they’ve adopted a chiplet design to improve yield (number of successful chips on one 30 cm wafer). Packaging is done in Taiwan and because it isn’t sexy, no one focuses on it. Without packaging, you have nothing. And chips etched in the US have to be flown to Taiwan for packaging. If China invaded tomorrow, and all the etching was done in the US, we would still have to fly the chips over for packaging.
Next part of you can’t just fabricate a CPU. A computer isn’t a CPU. There are other chips on the motherboard that control various features. For example, there’s a chip that controls the attached drives. It’s actually a little CPU in its own right, likely running a variation of Linux. Then there are chips to manage the power through the system. These are not simple voltage regulators, they are programmed to ramp up and down the current to keep the CPU running efficiently and cool. You likely have chips to handle all the slow speed IO, like USB ports. That’s not done directly by the CPU, there’s a separate processor for that. You can’t just make the CPU in the US and make a computer without all these other critical chips. Most are made in Taiwan, some in Japan, some in Korea, and some in China. That’s right, you already can’t assemble most electronic things for the US without Chinese made parts.
Next, you have to understand that Apple would buy chips from China. And so would Google and HP. If China took Taiwan tomorrow and the option was to go under or buy chips from a now Chinese controlled TSMC, Apple, Microsoft, Google, Meta, or whoever would buy the chips. Even if it meant entering into agreements that require more of the design to be done in a Chinese controlled company that would rip off the IP. Because going without sales (and maybe going under) is worse than maybe losing some US government sales. Plus, the US government will come around when there’s no option. In fact, it might make some things easier and they make even more money in the short term. If you go to these companies and say it might cost you a little bit more, but you insure your supply from being cut off, they would choose not to spend a little more. They will just assume they can continue with business as usual, buying chips from a Chinese controlled Taiwan. And they’ll be happy to do it.
Related, is the executives won’t believe it. Just as the Ukrainians didn’t believe the Russians would actually invade, and it was just a war game, as the Russians were setting up field hospitals on the Ukrainian border to treat the expected wounded, these business idiots don’t believe it will happen. I don’t even think it entered Tim Cooks little pointy head, as he sat through a screening of “Melania,” that China views the situation with anything other than a money lens. That’s because, like all business idiots, he views the world in a money lens. Why would China do something that would cost them money? The idea that China has felt humiliated and carved up by the West and this is about national pride is alien to them. Pride? If it costs you money? Tim Cook sat through a screening of what was essentially a bribe from Bezos to Trump to protect his money. Executives periodically line up, lips puckered, to pull down Trump’s piss-stained shorts and kiss his un-wiped ass. Money good. Must get more money. Corruption make more money faster.
For all these reasons, until China invades Taiwan, US tech companies are going to do a goddamn thing. And when China invades Taiwan, they will happily license their IP (their chip designs and process documents) to the Chinese controlled TSMC. The fact China will cut them out of the fucking loop once all the IP is stolen is lost on them. Just as they have done with every step of the way so far. Just as China is learning to cut Western designers out of other products. Why would you buy something at a premium, just because it has a Western label on it, when you can buy from the Chinese factory at a discount? Why would you buy an US branded computer when all the chips come from China, and it’s manufactured in a Chinese factory? It’s not like they’re going to get payback for the US putting spyware into the US networking gear bought by Chinese companies.
Once upon a time, there was a thing called the Marshmallow Test. You take a preschool aged child into a room and tell them if they don’t eat the marshmallow on the table, they’ll get that one and another one later. The idea is to see which kids will become doctors, lawyers, and CEOs, by delaying gratification, and which kids will scroll Tik-Tok and scratch their junk for a living. It turns out the whole thing was bogus, but it made a lot of parents try this at home and weep to see little Johnny gladly stuffing the first marshmallow in his fat little mouth. No delayed gratification. No future. Delayed gratification is not what business idiots learned. They learned to demand more marshmallows or else they’ll stop going potty in the right place. Just as they’ve learned to demand tax breaks, guaranteed loans, or other inducements to do the right thing.
If you think you’re going to get Tim Cook to buy a US made chip for his Macs or iPhones, well… he might. He might buy some from a Fab in Arizona to kiss Trump’s fat ass, ship them to Taiwan to be packaged, and then off to China to be assembled into an iPhone. Because Tim can’t package the chip in the United States. Nor can he make all the other parts of an iPhone in the United States – as just a practical matter. And as far as he’s concerned, it’s just keeping Trump happy. Just like he goes through the press conference (along with many tech leaders) announces a bunch of stuff but does nothing. Just like NVidia was supposed to invest 100 billion… I mean 30 billion… I mean up to 30 billion in OpenAI1. Business idiots just say words that have no meaning. He will do the bare minimum necessary to keep Trump happy so Apple doesn’t have to worry about the administration lobbing trade bombs at Apple. He will make the bare minimum number of chips in the US, though parting with that extra nickle every iPhone makes him weep.
Note that this story from Forbes does not invalidate my point. They will likely have US workers shove motherboards flow in from into a case and call that American manufacturing (because, remember, other parts come from other parts of Asia, including China). On their lowest volume product. And a vague promise for other stuff. All so they don’t have to pay a significant tariff on iPhones (their highest volume product).
Note that $20 in McDonald’s gift certificates counts as “up to 30 billion.” ↩︎
When I was overseas, a long, long time ago, it took me a while to understand, but confusion about what to do next was an opportunity for a bribe. I’m not talking about thousands of dollars here. I’m talking about a couple of bucks to get someone to stamp a piece of paper. They knew they had to stamp it, and they probably would without bribe, but the bribe made it happen a lot faster.
That’s what comes to mind when I see the confusion caused by the tariffs. I’m not saying anyone is expecting a bribe. After all, the ticket agent, conductor, or whoever, would never take a bribe. I’m just not sure who is supposed to offer the bribe? Are US citizens supposed to offer the bribe? Are foreign countries? Are the importers? (Like Apple).
Tuesday – Case Schiller home price index. Friday – CPI/PPI data
The other thing to watch is who is filing for refunds for tariffs paid. There are two levels of tariffs at play. The first are the tariffs in place before we started this descent into stupidity, and the yo-yo tariffs that have come on and off since “Liberation Day.” There is an orderly process for refunds, but not everyone is sure these refunds will be orderly. It may result in a class action suit to compel the refunds, but we’ll see.
CNBC estimates about 175 billion subject to refunds. That’s in line with other estimates from 130 to 175 billion. That’s considerably less than the additional tariff revenue collected since April 2025. That’s because the other tariffs were under different laws, which are still in place. For example, if there’s a finding of an unfair trade practice, a different law is applicable. The process under those laws requires some additional work. Whether it’s all kabuki theater or it will be done in good faith, I can’t say. (Despite my suspicions). I’m not an expert, but my guess is the section 122 tariffs (the sudden imposition of a 15% tariff on “global” imports that expires in 150 days) will be a bridge to get all the paperwork complete for other tariff statutes.
That said, the random 100% today and 20% tomorrow and then 55% the day after tariff announcements were under the International Emergency Economic Powers Act. That’s what the Supreme Court said was unconstitutional, because under their reading, it did not grant tariff authority. Section 122 requires Congress to reauthorize the tariffs in 150 days. I think Republican support for that is far from automatic. That means going into Labor Day (when most people start to think about elections), Congress people would have to explain why they authorized more taxes on American businesses.
Senate Seats Up for Grabs
The ability for Trump to set up a primary challenge to House and Senate candidates will have been long past, and it will be the Democrat challenger that candidates will be the big concern for Republicans. If the administration wants section 122 tariffs (the 15% just imposed) extended beyond late July, it will have to convince the Republican House and 22 Senate Republicans to vote for it, knowing they will hand their Democratic opponents a blunt instrument which will be used to beat them, repeatedly. Or, they will have to explain why tariffs on French wine and cheese is a national security issue.
This is an administration that is threatening Netflix with “consequences” if they keep Susan Rice on their board, given Netflix needs government approval for their upcoming merger with Warner Brothers. Their willingness, and the willingness of the billionaires who are ideologically aligned, to use every legal and possibly illegal means to keep at least the Senate will be used. These people realize if the Democrats do come to power, they won’t retaliate in the same way the Trump administration will retaliate. A Democrat president will probable drag their feet on firing the partisan hacks, like Brendan Carr, when they get into office. So why should they care about what Democrats might do them, should power change.
Nor is it clear that the election will not result in massive chaos. As was evident in the 2020 election, claims of fraud went forward even though it (implicitly) invalidates Republicans that won down-ballot. They might have a Democrat win a House race, and a Republican win the Senate race, but still claim the vote was fraudulent. And the 40% or so of the country that’s “ride or die” with Trump, they may even be more amped up than 2020. Along with the fact social media execs have shifted right, ff not captured by a system of patronage, that suggests they’ll be protected if they help Trump. For example, showing they are willing to exempt Apple ICs from tariffs, but also “mentioning” that Apple News appears to favor a left-wing liberal agenda.
2026 is not in the bag for a Blue Wave. Nor is 2028 in the bag for a transfer of power. At this point Trump is still respecting the decision of the courts, if only grudgingly, and sometimes completely with contempt. If the energy is to impeach and prosecute him for stealing billions of dollars (for example, transferring US funds to his board of pieces of shit), he may pull off the last guard rail. A lot of his supporters among the elite are not ride or die. They know they may not go to real jail if caught for criminal activity, they may lose a lot of money. But if the deal is better to back Trump over the US constitution, they may back Trump.
I would like to think that between tariffs and immigration enforcement Republicans would be handed a soul-searching political ass-pounding. But social media feeds can have an insidious impact on political opinion. Just like Tik-Tok’s algorithm fed several many times more images of murdered Gazans than murdered Israelis, and helped from the initial push for protests of Israel. Then Israel managed to provide more than enough reason to protest their invasion of the Gaza strip and continued occupation of the West Bank. But that’s for another day. The point is, that among Tik-Tok users, those videos were very effective. And I think, with the transfer of Tik-Tok away from China to Trump’s friends, I think the feeds will be manipulated to stunt what should be an epic smashing.
A side note if you think other governments pay tariffs. You are ignorant. Many people have explained how tariffs work and it’s the company importing the good or service that pays the tariff. Since China doesn’t import anything into the United States, it’s US companies like Wal-Mart that import Chinese made goods, it’s the US company that pays the tariffs. There are so many explanations of this around that if you don’t understand it, you’re a fucking idiot.
It was not about anything other than Article I specific powers that Congress has and the statute under which Trump was operating. Let’s say that despite their best efforts, Republicans lose the White House in 2028. And 2029, despite the Sargent at Arms arresting him to count the electoral votes, Democrats take over. A Democrat decides to cut tariffs on everything, but double them on hydro-carbons. Because the climate is an emergency and the president has these emergency powers. And the three justices who “crossed the line” understood that and the law.
I think they would have easily changed their tune had the tariffs been enacted by a Democrat. I think the mask has been off with Alito and Thomas for some time. They aren’t concerned with the about a Democrat using those powers, because they would stop that in a heartbeat. They are not there for precedents or the law. I think they’re there for a political agenda. This should have been a 9-0 decision. It should have been a slam dunk. Nothing in the statute indicated Congress gave up the power to tax.
My hope is that a Democrat House and (more importantly) Senate majority is in place when Alito or Thomas leave their posts. That way the majority leader could discover a tradition that says the appointment of a new judge can wait until the next president. You know, pulling a Mitch McConnell. Clarence Thomas is 77 and Alito is 75. The average age for upper income Americans is in the 80s. They might go for six more years, but they might not. Or it might be evident that they cannot. I don’t know what will happen if a dementia ridden judge refuses to step down because the president is the “wrong party.”
And let’s face it, we no longer care what the Bar Association thinks about qualifications, temperament, or caliber of individual. The court has come out as partisan so we’re going to pick the youngest partisan hack we can find that has a credible CV for the Supreme Court. An existing federal judge who we think will advance our agenda. The idea we’re going to pick our best jurists for the role is a quaint notion.
What the decision was not about was any kind of split or rebuke of the president. For the three judges who “crossed over,” their basic sense of the job and their sense of their legacy probably prevented them from voting to protect the tariffs. But only in this narrow instance. From the earlier immunity decision, we have plenty of evidence what the conservative justices think the limits of their president are. To varying degrees, they support a stronger, less restrained executive. (And thankfully it’s openly written about, so we know the Unitary Executive isn’t just a liberal brain disease).
Under what scenario does cutting rates, along with heavy deficit spending, not lead to inflation? If productivity expands from AI and automation. Setting aside my disbelief in the mechanics that would allow this to play out in a short-term basis, it is reminiscent of the supply side argument from the 1980s. You’ll still find people who believe in the argument to this day, even though the evidence has eviscerated it. But let’s hop into the way-back machine to 1980-something.
The argument was that inflation was a result of demand suddenly outstripping supply. If you lower taxes or raise spending, you stimulate the economy (that was when congress was not so politically deranged they couldn’t raise taxes to slow the economy, if needed). Other levers could be using the reserve requirement to stimulate or depress lending or raise the federal funds rate. By the early 1980s, and a brutal several months of extremely high rates, inflation was on its way down. But an interesting phenomena was emerging. The Philips curve, the statistical relationship between unemployment and inflation, began to ratchet up. For the same level of unemployment, it seemed like we were getting higher levels of inflation.
The solution was to push out the supply curve1. And if the solution sounds similar to every single Republican proposal you ever hear, it’s because it is. Cut taxes, especially among the investing and business class, and remove the pesky red tape, safety regulations, and environmental regulations. That would “unleash the animal spirits” of American enterprise and the supply curve would be pushed out to achieve higher levels of output (lower unemployment) without inflation. Well, we did cut taxes and Regan and trigger what (at that point) had been record deficits.
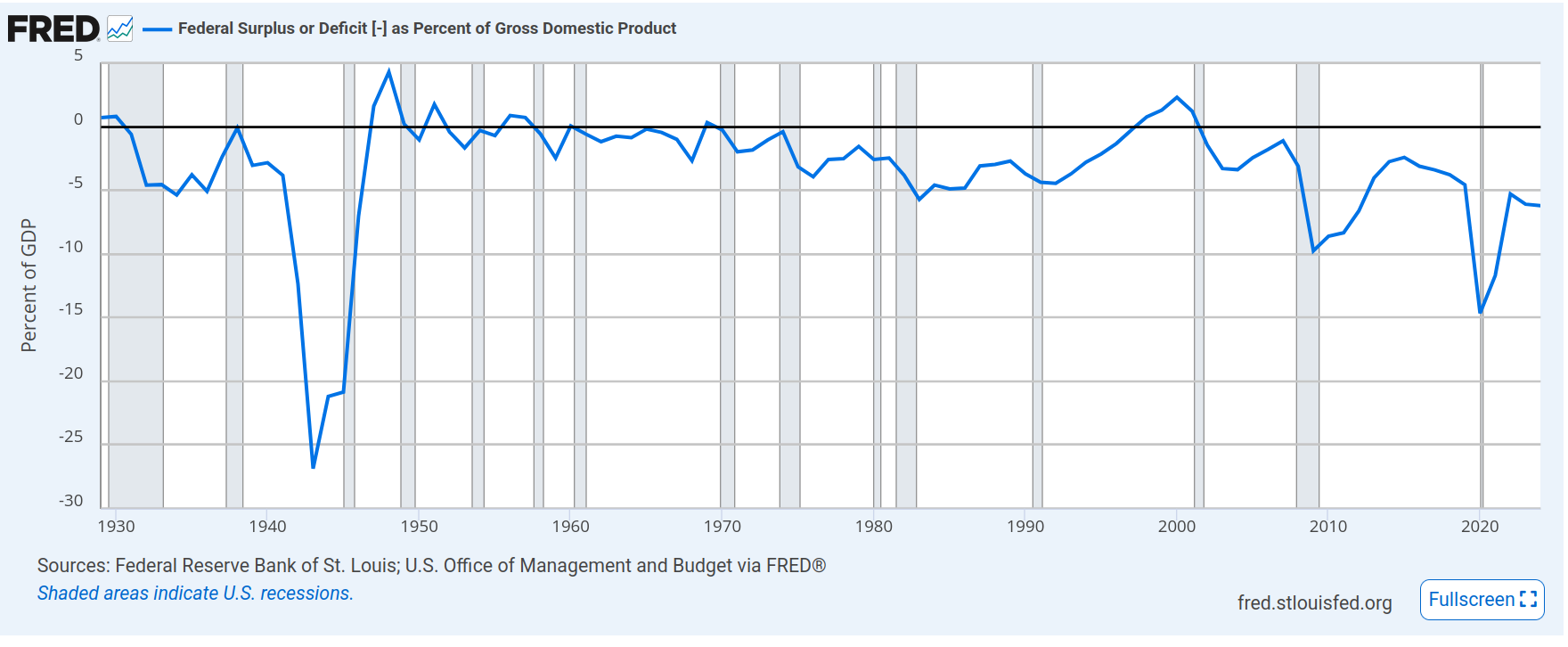
As we can see, except for World War II and the great depression, we’d never seen deficits so large as under Regan. And now we can’t even get to striking distance of a surplus. But that’s okay. We’ll have deficits now, but the economic activity will make up for it, right? Meh – not so much. They say George H.W. Bush lost the 1992 election because he broke his promise of no gnu taxes. And I beg to differ. Neither yaks, gnus, oxen, or other ruminants had their taxes raised. Under the profligate Democrats, from 1992 through 2000, deficits actually shrank and we had a surplus. Until the next Republican figured out how to drive massive deficit spending again (and almost put is into another great depression – but that’s a story for another time).
Any economist, in the 1980s, believed the supply side of the demand and supply curves could expand out, achieving greater well-being with limited changes in the price level. It just took time. It takes time to build a factory or get a business running. Because of improvements in technology and productivity, over a period of 5, 10, or 15 years, the supply curve slowly pushes outward.
That wasn’t the supply side argument. It argued that you could drive the supply curve to higher levels of productivity in the short term, without inflation. Not 5 or 10 years, but 1 or two years. Tax revenues would shoot up and cover the short term deficits. But, at the end of the day, there was no great well of untapped capacity in the United States that would have allowed such an expansion. And low and behold… there was no great increase in production and deficits went up. To avoid inflation, Volker had to keep rates high and jack up the Fed Funds rate again. No great swell of tax revenues came in to fix the deficit issue.
But the 1980s were a decade of great prosperity and economic growth, right? Yes, as the Fed and the administration and congress had dueling economic policies. The don’t tax but spend a lot policy of the Republicans had to be throttled by the interest rate policy of the Fed to avoid a return to high inflation levels. Maybe Volker should have just said “fuck it” and let the deficit spending result in massive inflation, but he kept the brakes on. So yes, the 1980s was a great decade because we mashed the accelerator and the brake at the same time, but just so the car could move forward.
The argument evolved from the short term variant to a new variant (much like COVID) that was more congruent with reality. That was the long term supply side argument. “See, we were right, the supply curve eventually did shift right.” Over a period of several years, just as many economists would have argued before the ill-conceived economic experiment. Their revisionists argue it was about long term movement of the supply curve, you just mis-understood us on the short term stuff. That’s not an evolution of the argument to take into account new realities, but rather how intellectually dishonest people (liars) cover their tracks.
Which brings us to the present. The president wants to do what Regan never would have dared, because Regan believed in America and American institutions. He wants to make the Federal Reserve a tool of the administration. He wants them to drop rates at the same time he’s engaged in deficit spending. (And like any good autocrat, skim a little off the top and drop it in an account in Qatar). The claim is there is a great untapped reserve of unproductive people who could be rendered so much more productive, that we’ll get more output at the same level of prices.
This argument is completely predictable. Lower taxes, lower regulation, and lower rates and the economy will blossom. The magic will be AI that will suddenly allow people to produce so much more that the increased demand will be satisfied at the same price level. We’ve had AI in various forms for a few years now. We are not seeing any change above the historical bounds for productivity. In the last couple of years there hasn’t been any sign that productivity is being impacted at all. In fact, computers have coincided with a drop in productivity since their wide-spread introduction in the 1970’s. But that was a key to the supply side argument as well, the animal spirits would be unleashed, in part, through productivity.
I want to be clear that in the 1980s I believed the argument the supply side economists were making. I’m writing this, as someone who took the argument seriously, looked at the outcome, and then realized the argument was wrong. And I see why it didn’t work, and never would have worked, even if Volker had dropped rates. I look at it this time and see the same argument being made, except by clearly worse people. We drop taxes on (disproportionately) the wealthy, we lower safeguards around our safety and health, and now we drop interest rates (which will cause the assets of the wealthy to inflate), and we’ll get this ground swell of growth without inflation. We are making the same mistake, twice.
That takes me to my next topic, which is the Iran strike. Now we have a 10 to 15 day timeline. That puts it in the range of March 2 to March 7. The next new moon is March 18. However, as I explained, that doesn’t matter if the moon is set. Moon set, however, will be between 6 AM and 8 AM, meaning there will be moon all night, with March 3 being a full moon. Darkness is good for US operations because we’ve focused on being able to see at night, something that’s expensive and out of the reach of many militaries. The darker it is, the harder it is to spot planes, helicopters, and drones. The next good opportunity after March 7 is about a week later, March 15. March 15 is a Sunday, so the strike would get full Monday morning news coverage. Beware the ides of March?
I should state, for clarity, that there are no Supply and Demand curves. It’s a pedagogic tool used to explain concepts around issues like how economic output and price level interacts. That sometimes the nominal growth you see comes in the form of inflation and not more goods and services. ↩︎